For many growing businesses, the monolith was never the villain. It helped the product reach the market, kept early development manageable, and gave teams one clear place to build, test, and deploy. The problem begins later, when the same application starts carrying too many responsibilities. A checkout update affects inventory logic. A reporting change slows release planning. A single database becomes the hidden meeting point for every feature, team, and risk.
That is when the shift from monolith to Python microservices becomes less of a technology upgrade and more of a business continuity decision. The goal is not to tear down what already works. The smarter path is to reshape the system around scale, ownership, and safer change.
Why Rebuilding Everything Is the Wrong Starting Point
A complete rewrite may appear appealing in theory, yet live production environments are rarely as straightforward as architectural models suggest. Legacy systems carry years of embedded business logic, exception handling, user patterns, regulatory requirements, and undocumented edge cases. Attempting to rebuild everything in one motion can turn modernization into an expensive and extended standstill.
A stronger migration approach keeps the monolith stable while carefully chosen capabilities are moved into independent Python services. This helps teams lower risk without slowing progress on scalability and faster releases. For an eCommerce business, payment functionality is usually too sensitive and dependency-heavy to extract first.
This approach gives teams room to learn before they touch the most fragile parts of the system.
Reading the Monolith Before Breaking It Apart
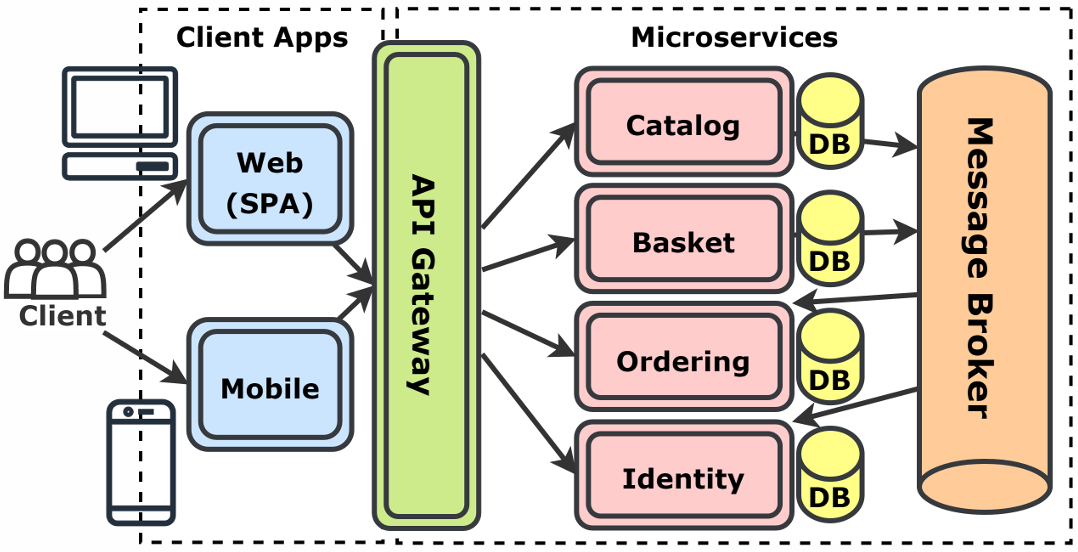
The journey from monolith to Python microservices should begin with architecture discovery, not code extraction. Teams need to understand which modules change often, which features slow releases, which database tables are shared across too many workflows, and which business functions already have natural boundaries.
Useful questions include:
- Which feature needs independent scaling?
- Which database tables reveal hidden coupling?
- Which workflow has clear inputs and outputs?
- Which module creates the highest release friction?
- Which domain can be separated without disturbing core revenue flows?
This is where many migration efforts fail. Teams split applications by technical layers instead of business capabilities. A “database service,” “logic service,” or “utility service” often increases dependency rather than reducing it. Stronger boundaries usually come from business domains such as billing, inventory, customer profile, order management, notifications, and analytics.
Choosing Python Frameworks With Purpose
A strong migration strategy recognizes that not every service belongs in the same Python framework. The right framework should be chosen according to workload characteristics, performance needs, team experience, and long-term supportability.
FastAPI works well for API-first services, async workloads, AI model interfaces, real-time integrations, and high-throughput endpoints. Django still has value for admin-heavy domains, complex business logic, and applications that already depend on its ORM and ecosystem. Flask remains practical for lightweight APIs, migration adapters, internal tools, and focused utility services.
This is where experienced python web development services can help teams avoid framework-driven decisions. The question is not “Which framework is best?” The better question is “Which framework fits this service boundary without adding unnecessary weight?”
The Database Is Usually the Real Monolith
Code can be separated faster than data. That is why database migration deserves serious attention in any move from monolith to Python microservices. Many monoliths look modular at the code level but remain tightly connected through shared schemas, foreign keys, stored procedures, reporting queries, and transactional assumptions.
A temporary shared database may be acceptable during early extraction, but it should not become the permanent design. Over time, each service needs clear data ownership. The order service should own order data. The inventory service should own stock data. The billing service should own invoice and payment records.
That shift changes how consistency works. Teams can no longer depend on one large transaction across every workflow. They need event handling, retries, compensation logic, audit trails, and reconciliation processes. For instance, if an order is placed but payment confirmation arrives late, the system must know whether to reserve stock, notify the user, retry payment validation, or release the inventory after a timeout.
Event-Driven Design Prevents Tight Coupling
Many companies move to microservices and accidentally build a distributed monolith. Services are technically separate, but every request still depends on a chain of synchronous API calls. If one service slows down, the entire workflow suffers.
Event-driven design helps reduce that risk. Instead of making services call each other whenever something changes, one service can send out an event and the others can respond separately. When an order is placed, the order service sends the event, and inventory, notifications, analytics, and fulfillment can act on it without being tied to the same flow.
Kafka, RabbitMQ, and Redis Streams all support event-driven systems, but each fits different requirements. Kafka is effective for durable streams and workflows that benefit from replay. RabbitMQ is useful for background jobs and task-based messaging. Redis Streams works well for lighter, faster-moving event flows. The best choice depends on message durability, throughput, ordering expectations, and operational strength.
Operations Must Mature With the Architecture
A Python microservices migration is incomplete without deployment discipline. Docker, Kubernetes, CI/CD, automated testing, health checks, rollback plans, secrets management, and environment controls are not optional extras. They decide whether independent services become easier to operate or harder to trust.
Observability matters just as much. In a monolith, one request usually stays inside one runtime. In microservices, the same request may pass through an API gateway, two services, a queue, a database, and a third-party system. Without correlation IDs, distributed tracing, centralized logs, metrics, and alerting, teams lose visibility exactly when they need it most.
Security also becomes a larger architectural concern. Once services are separated, each boundary must be treated as a trust boundary. That means authentication, authorization, encrypted communication, API versioning, rate limits, and audit logs should be built in from the outset.
Scaling Without Losing the Product’s Memory
Strong migrations recognize that the monolith contains years of operational knowledge. They do not discard that logic for the sake of a new architectural model. They move carefully, validate reliability at each stage, shift data ownership over time, and allow the existing system to reduce naturally as the new one becomes stable.
That is the real value of going from Monolith to Python Microservices. Businesses gain independent scaling, cleaner ownership, faster releases, and stronger integration paths without gambling the entire product on one rewrite. For companies also exploring intelligent automation, recommendations, or AI-powered user experiences, this foundation can work alongside artificial intelligence web development services to support future-ready digital systems.
Microservices should not be treated as an escape from the monolith. They should be treated as a disciplined way to let the business keep growing without rebuilding everything that already works.